Appearance
ComfyUI 笔记
课程链接:https://www.bilibili.com/video/BV1ahJtzeEB1
补充:加载 LoRA 微调大模型:https://www.bilibili.com/video/BV1s142187Yx
二、第二节
空 Latent :控制图片宽、高、批次
checkpoint 加载器:选择并加载大模型
三、文生图
案例 1:搭建基本的文生图工作流
正向提示词:想要什么
负向提示词:不想要什么
![]()
扩展知识:Transformer — Attention is All You Need 论文(AI 史上重要的里程碑)
Clip 模型的作用:文本编码和图像编码
文本编码:将文本转化为 特征向量 (Transformer 架构),对应 ComfyUI 的 Clip 文本编码器
写提示词的技巧:先写质量词,再写主体,再写氛围
- 参考:杰作,高质量,极致的细节+一个女孩,双马尾,蓝色头发,校服+教室背景,动漫风格
- 越靠前的词汇,权重越高
- 负面提示词组包:embedding: easynegative
图像编码:将(大模型的)训练集转化为特征向量(ViT、ResNet 架构)
K 采样器(比喻:坐标轴+特征向量)
- 随机种、运行后操作(定义随机种如何变化)
- 步数:降噪的次数(比喻:擦玻璃)
- 步数越少:越模糊、细节越少;步数越多:越清晰、细节越多
- 边际效用递减
- 参考值:生图步数 20-30 即可
- CFG:控制图片与提示词的匹配程度
- CFG 越高图像与关键词越匹配、越相近
- CFG 越低,AI 越放飞自我,自由发挥空间更多
- 参考值:生图 CFG 值 5-8 即可
- 调度器
- 作用:控制降噪的方法
- 参考值:karras
- 采样器
- 控制降噪的程度
- 参考值:dpmpp_2m/dpmpp_2m_sde
- 降噪(图生图)
文生图的底层逻辑
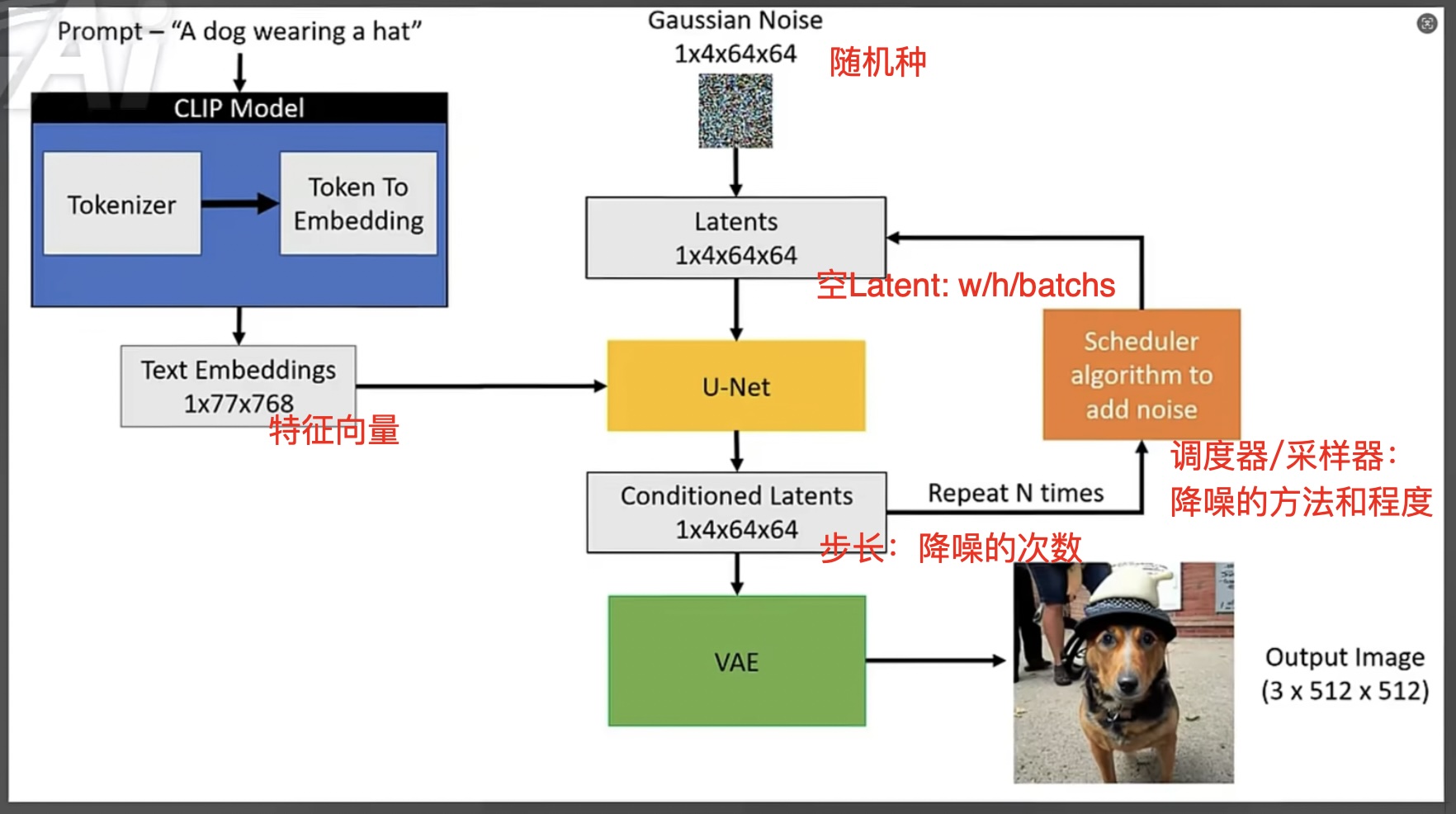
- StableDiffusion 用的 Diffusion 模型,即扩散模型
- 扩散模型的运行机制:为噪声图像不断的降噪,从而生成目标图像

随机种决定 Gaussian Noise 的分布规律,从而影响最终生成的图像
- U-Net 作用:预测下一步降噪的图片以及减少噪声
- VAE 作用(比喻:转换器):将 Latent 图像变为像素空间图像
四、图生图
搭建基本的图生图工作流
K 采样器的降噪值
- 参考值:图生图一般为 0.35-0.6 之间,近似原图
VAE 加载器
- VAE 一般由大模型提供,但是有时候大模型匹配的 VAE 不好,导致图生图的结构颜色偏暗,这时候就可以通过 VAE 加载器加载 VAE 模型
案例 3:使用 VAE 加载器加载专门的 VAE 模型,而不是用大模型自带的
图生图的底层逻辑
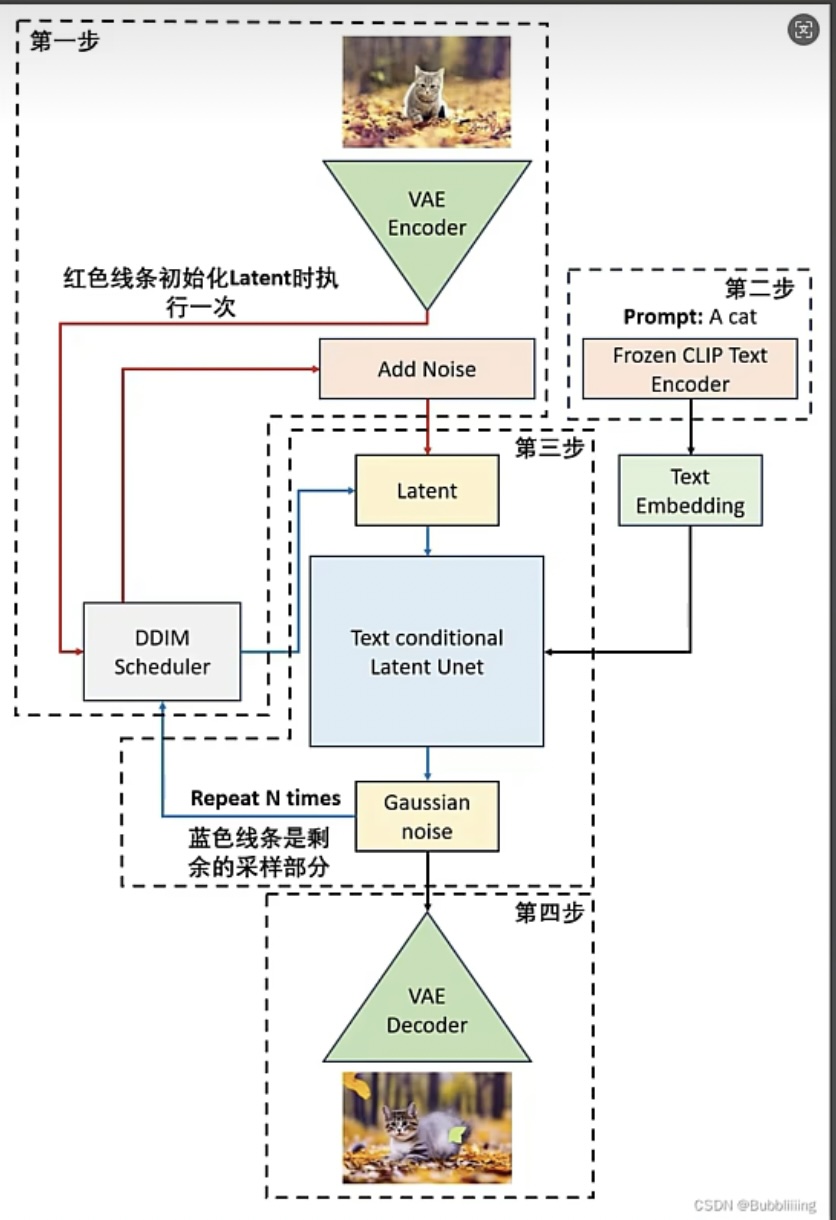
VAE 编码/解码器:处理潜空间图像与像素空间图像的转换
最终图片生成的整体风格:大模型的影响>提示词的影响
五、AIGC 常用网站
网站:
- LibLibAI
- NovelAI.Dev 法术解析
- Promlib 专注于提示词的构建和可视化
- CivitAI 模型库庞大
- 大模型 LoRA Controlnet 模型 VAE 模型 IPAdapter 模型等
- GitHub
- HuggingFace 专注于 AI 领域和模型存放
- joy-caption 反推提示词
理解 LoRA:小模型,体积小,10MB,几百 MB,但是却能基于大模型改变最终生图的风格,或是聚焦于某一角色的特定形象
大模型和 LoRA 的存放位置
- 大模型:ComfyUI/models/checkpoints
- LoRA:ComfyUI/models/loras
Flux 模型
六、高清放大
一次放大
- 参考值:系数 1.5;K 采样器降噪 0.5
- Latent 按系数缩放、K 采样器
二次放大:SD 放大
- 原理:分块放大
- 节点:SD 放大、放大模型加载器
三次放大:图像通过模型放大
- 节点:图像通过模型放大、放大模型加载器
案例 4:三次放大工作流
七、Controlnet 控制图像
Controlnet 作用:线条控制、姿势控制、深度控制、面部参考、局部重绘等
说明:在 ComfyUI 工作流中添加 LoRA 节点和 ControlNet 节点的核心目的是增强生成图像的控制能力和风格多样性
Controlnet 模型:
- Lineart
- Softedge
- Openpose 人物姿态控制、面部控制
- Controlnet ADV(Controlnet 应用旧高级)
- DW 姿态预处理器
- Depth
SD1.5 和 SDXL 模型的区别
- SD1.5 训练集是 512x512
- SDXL 的训练集是 1024x1024
案例 5:Lineart 线稿 为动漫线稿上色
案例 6:Softedge 软边缘
案例 7:Openpose + Softedge 多重 Controlnet
案例 8:Depth 控制图片的深度
八、AI 换脸 IPAdapter
核心节点:
- IPAdapter FaceID 加载器
- 应用 IPAdapter FaceID
- Clip 视觉加载器
- IPAdapter FaceID 模型加载器
SD 案例 9:图片换脸
九、综合案例:老照片修复工作流
TODO
十、Flux 进阶
Flux 案例 1:基础 Flux 工作流
sd, sdxl, flux
flux fp8, flux kcontext
主流的模型类型:ControlNet, LoRA, IPAdapter
vae 潜空间图片
- 比喻:“调色滤镜”
- 一般配合大模型使用,有些大模型也自带 VAE
- 文件一般放在 ComfyUI/models/vae/ 或 stable-diffusion-webui/models/VAE/ 目录下
- 加载方式:你在工作流里插个 VAE Loader 节点,让大模型输出的潜空间走对应 VAE 解码
- 经验规则:如果模型画面发灰、发暗、颜色怪,大概率是 VAE 不对
除了 SD / Flux,还有哪些绘图大模型上了台面?
扩散类:
- Stable Diffusion(SD/SDXL 系列) – 老牌主流,生态最大
- Kandinsky(俄罗斯 Sber AI 出的)– 支持文本+图像输入,融合能力强
- PixArt 系列(PixArt-Alpha、PixArt-Σ 等) – 国产团队搞的高分辨率扩散模型,媲美 SDXL
- DeepFloyd IF(StabilityAI 出的)– 类似 Imagen 的高保真度扩散
- Auraflow / Playground v2 – PlaygroundAI 推出的高质量扩散模型,社区热度高
- Kolors(Kuaishou 出的)– 国产快手系,风格独特,写实强
非扩散(Transformer 类 / 新架构):
- DALL·E 3(OpenAI)– 强 prompt 理解,画插画文字能力最强
- Ideogram – 加拿大团队,专攻海报/文字可控生成
- MidJourney – Discord 生态王者,画风审美公认在线
- Google Imagen / Parti – 实验室级别,论文效果惊艳
- Adobe Firefly – 集成在 Photoshop/Illustrator,用得人多
- Runway Gen-2 – 更偏视频,但图生图质量也不错
国内新秀:
- 文心·一格(百度) – 走国风+实用商用路线
- 通义万相(阿里) – 电商图、广告图生成很强
- 秒画(腾讯) – WeChat 生态内测用得多
- 智绘(字节跳动) – 抖音系工具
总结=>类比一句:
- SD → Photoshop 插件化(开放、自由、生态最大)
- Flux → Figma 风格的新锐工具(轻量、快、现代架构)
- DALL·E / MidJourney → Apple 风格的封闭精品(自己玩得爽,但不开源)
- 国内系 → 拼多多/淘宝生态的垂直神器(商用、定制、接地气)
十一、Flux 进阶:去 AI 感
TODO