Appearance
20260226-面试复习
1、Go GMP 模型
- G:Goroutine 局部队列、全局队列
- M:OS 线程
- P 的数量(GOMAXPROCS 环境变量):真正跑 Go 代码的 M 的数量
GMP 的核心思想就是通过引入 P 层,把调度权和执行权分开,让 Go 运行时自己掌控调度节奏,而不是完全依赖操作系统内核的线程调度
即通过 P 层将成千上万的 goroutine 调度到有限的 OS 线程上,保证效率
2、Slice 相关
底层结构:slice 是一个结构体,有 ptr、len、cap 字段,真正的数据在 ptr 指向的底层数组中
扩容机制:append 时,当新长度超过 cap 时(len+新增 > cap)触发扩容,具体流程是按 cap 大小计算新容量来创建新数组,然后拷贝原 slice 的 len 个元素,并返回指向新数组的 slice
3、Map 相关
底层结构:Go 的 map 底层是哈希表,每个桶(bucket)最多存 8 个 key/value,如果同一个桶满了,多余的元素会挂在 overflow 链表
扩容机制:当 load factor 超过阈值触发扩容时,会创建新桶并逐步把旧桶(包括 overflow 链)按 hash 搬到新桶,访问和写入期间也会迁移
4、我的 Go 语言的理解
- 工程优先。没有异常、继承等高级语言特性,牺牲表达力,让大型项目更稳定
- 并发模型。CSP/通信顺序进程,通过通信来共享内存。并发语意表达强且效率高,适合高并发服务
- 代码编译成二进制文件,部署时不依赖虚拟机,因此镜像非常小
- Go 抽象设计,没有沿用传统 OOP 继承,而是鼓励通过接口解耦,多用组合少用继承
Kafka 相关
Kafka 是通过分区来拓展吞吐量的;通过副本/主备/选举来保证高可用的
1、在同一个消费者组(Consumer Group)里,一个分区在同一时刻只能被一个消费者实例消费 -> 保证一致性
- Kafka 单分区内消息有序
- Kafka 的并发扩展单位是 Partition -> 关键词:分区数/并行能力/吞吐量
- 每个 Partition 只会分配给组内一个 Consumer
总结:
- 同一消费者组内,一个分区只会分配给一个消费者实例,以保证顺序和 offset 一致性。
- 并发能力由分区数决定。Kafka 的扩展单位是 Partition,而不是 Consumer。
2、同一个 Consumer Group 里:一个消费者可以同时消费多个分区,但一个分区在同一时刻只会被组内一个消费者消费。
RabbitMQ 相关
1、理解 QoS:每个消费者一次最多持有多少个未 ACK 的任务。
为什么不是“同时处理多少任务”:“同时处理”指的是消费者的内部实现,比如用多线程或协程并发执行任务。这由你的代码决定,与 QoS 无关。
2、理解每个指标的含义
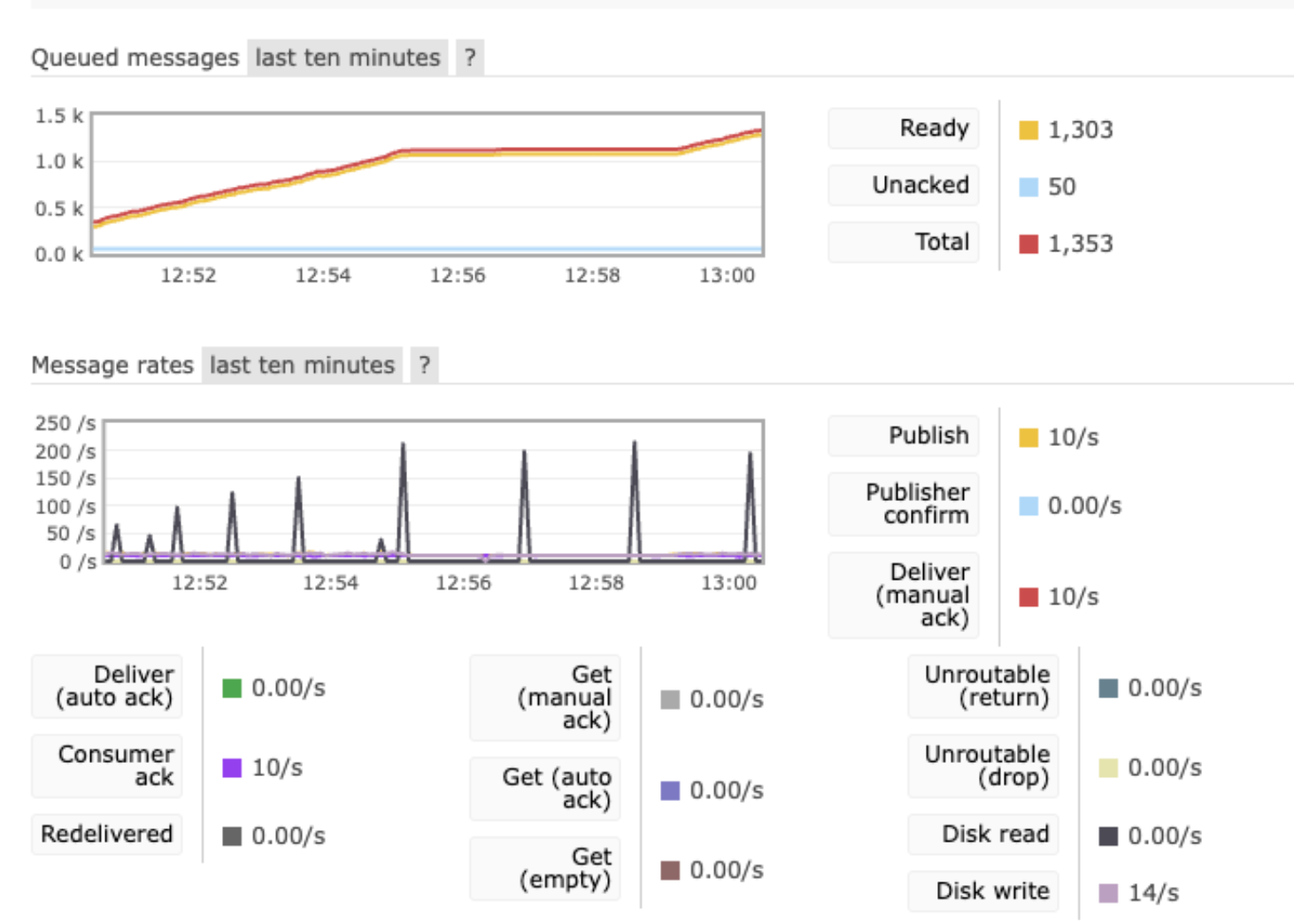
- Publish = 10/s 每秒进入队列的消息数 代表上游写入压力
- Deliver (manual ack) = 10/s RabbitMQ 每秒推送给消费者的消息数(需要手动 ack) 这是“发出去”的速率,不是“完成”的速率
- Consumer ack = 10/s 消费者每秒确认完成的消息数
gRPC 相关
1、四种调用方式
unary 和 steaming
- Unary
- Server streaming(服务端推送,如股票行情)
- Client streaming(客户端上传大文件、分块日志)
- Bidirectional streaming(聊天、实时协作、双向数据管道)
相关问题:
- gRPC 为什么比 REST 快?二进制、HTTP/2 多路复用、长链接复用
- 为什么 streaming 比多次 HTTP 请求好?避免频繁的 TCP 握手、减少 header 重复传输、实时性好
- gRPC streaming 底层靠什么实现?HTTP/2 frame、flow control、窗口大小
- 什么时候不能用 streaming?简单的CRUD、不需要实时性
- gRPC 原理?streaming 是基于 HTTP/2 多路复用,一个 TCP 连接里可以有多个 stream,gRPC 把 stream 抽象成连续消息
- 你用过 streaming 吗?streaming 的核心是基于 HTTP/2 的双向流,它在一个连接中持续传递多个消息,而不是分为多个HTTP请求。这种方式更适合数据量大和实时性高的场景。
- Streaming 的背压(flow control):消息流控、应用层控制使用 channel 和 buffer
- gRPC 的生命周期控制 ctx、keepalive、心跳等
Docker 相关
1、Dockerfile 命令
WORKDIR COPY/ADD RUN CMD/ENTRYPOINT EXPOSE ENV/ARG
2、多阶段构建
构建阶段 -> 运行阶段(二进制文件)
dockerfile
# 阶段1:构建阶段(命名为 builder)
FROM golang:1.22-alpine AS builder
WORKDIR /app
COPY go.mod go.sum ./
RUN go mod download
COPY . .
RUN CGO_ENABLED=0 GOOS=linux go build -o main .
# 阶段2:运行阶段(最终镜像只用这一层)
FROM alpine:3.19
WORKDIR /app
COPY --from=builder /app/main .
EXPOSE 8080
CMD ["./main"]3、利用缓存构建镜像
先 COPY go.mod/go.sum → RUN go mod download → 再 COPY . .
为啥这样有效?因为源代码(.go 文件)天天改,但 go.mod / go.sum 改得很少(只有加/删依赖时才变),所以我们故意把“最不容易变的部分”先做:
dockerfile
# 第一步:只拷最稳定的文件(改动极少)
COPY go.mod go.sum ./
# 第二步:下载依赖(网络最慢、最耗时)
RUN go mod download
# 第三步:拷全部源代码(天天改)
COPY . .4、CMD 和 ENTRYPOINT 区别?
- CMD 会被 docker run 命令覆盖,而 ENTRYPOINT 不会
- 两者通常配合使用,ENTRYPOINT 指定主程序或脚本,CMD 来控制参数
dockerfile
ENTRYPOINT ["./entrypoint.sh"]
CMD ["--prod"]5、COPY 和 ADD 现在推荐哪个?为什么?
推荐使用 COPY 因为它的功能单一,这意味着可预测、安全,只有特定场景才 ADD,例如远程下载、解压等
6、ARG 和 ENV 的区别?
ARG 是给镜像构建使用的一次性参数,而 ENV 会成为容器运行时的环境变量
dockerfile
# ARG 只在 build 时有效
ARG APP_VERSION=1.0
ARG HTTP_PROXY=http://proxy:8080
RUN echo "构建版本是 $APP_VERSION" # 可以用
RUN wget --proxy=$HTTP_PROXY ... # 可以用
# ENV 会进入最终镜像
ENV APP_VERSION=1.0
ENV PORT=8080
CMD ["./app", "--port=$PORT"] # 运行时能读到Agent 相关
1、Multi-Agent 系统:LangGraph 状态机、用LlamaIndex查文档、ReAct 设计模式
2、LlamaIndex 和 LangChain 最简单的代码:文档问答RAG
LlamaIndex
py
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
# 全局设置(一次就好)
Settings.llm = OpenAI(model="gpt-4o-mini")
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small")
# 1. 读文件 → 自动切块 → embedding → 建索引
documents = SimpleDirectoryReader("你的资料文件夹").load_data()
index = VectorStoreIndex.from_documents(documents)
# 2. 直接得到一个能回答问题的引擎
query_engine = index.as_query_engine(similarity_top_k=5)
# 3. 问
response = query_engine.query("公司2025年Q4的营收目标是多少?")
print(response)
print(response.source_nodes) # 看引用的原文片段LangChain
py
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_community.document_loaders import DirectoryLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain.chains import create_retrieval_chain
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI(model="gpt-4o-mini")
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# 手动:读 → 切 → embed → 存
loader = DirectoryLoader("你的资料文件夹")
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = FAISS.from_documents(splits, embeddings)
# 检索器 + chain
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
prompt = ChatPromptTemplate.from_template("根据以下上下文回答问题:\n{context}\n问题:{input}")
chain = create_retrieval_chain(retriever, prompt | llm)
# 问
result = chain.invoke({"input": "公司2025年Q4的营收目标是多少?"})
print(result["answer"])3、请你解释下什么是 RAG?
数据准备阶段:文件、资料等 -> 提取文本 -> 文本分词器分块 -> 将分块后的文本通过向量大模型转化为向量坐标 -> 将向量坐标存储到向量数据库里
提问阶段:用户提问 -> 向量大模型将提问转化为向量坐标 -> 使用提问向量坐标去向量数据库里查找相关度最高的句子 -> 将这些句子携带再提示词里给到大模型 -> 大模型基于提示词和相关句子生成回答