Appearance
数学基础
- 导数的基本概念
- 理解导数的定义
f'(x) = lim(h→0) [f(x+h) - f(x)] / h - 推导常见函数的导数
- 理解导数的定义
- 微分的基本概率
- 微分是微积分的一部分,微分专门研究函数变化率
- 从 导数的定义 推导 微分公式
- 微分公式告诉你如何算这个梯度(偏函数组合)
- 没有微分公式 → 不知道参数怎么改 → 模型训练不动
- 梯度下降算法 导数 + 微分
- 导数:一元函数/单输入函数的导数
- 微分:多元函数/多输入函数的导数(偏导数 + 向量/梯度)
- 偏导数 = “固定其他变量,只看一个变量变化时的斜率”
- 梯度 = 向量,把所有偏导数组合起来
- 负梯度:最快下降方向,更新参数(神经网络)
| 属性 | 单输入 f(x) | 多输入 f(x,y,...) |
|---|---|---|
| 输入 | 1 个数字 | 多个数字 |
| 输出 | 1 个数字 | 1 个数字(也可以向量,但这里先标量) |
| 导数 | 一个数 | 每个输入都有一个偏导数 → 组成向量(梯度) |
| 几何意义 | 曲线斜率 | 高维曲面坡度 → 哪个方向上增长快 |
- 链式法则
- 这是反向传播的核心!
如果 z = f(g(x)) 则 dz/dx = (dz/dg) × (dg/dx)- 神经网络例子:
输入 → 线性层 → 激活函数 → 损失 x → z=Wx+b → a=σ(z) → L --- 反向传播: ∂L/∂W = (∂L/∂a) × (∂a/∂z) × (∂z/∂W) ↑ ↑ ↑ 损失对激活 激活对线性 线性对权重
神经网络里,我们用微分公式 + 链式法则 → 算偏导 → 组成梯度 → 更新参数
| 叫法 | 适用 | 意义 | 类比 |
|---|---|---|---|
| 微积分 | 整体数学领域 | 包含微分 + 积分 | 数学大类 |
| 微分 | 函数变化率 | df | “微小变化” |
| 导数 | 单输入函数 | df/dx | 曲线斜率 |
| 偏导数 | 多输入函数 | ∂f/∂x_i | “单个方向斜率” |
| 梯度 | 多输入函数 | ∇f | 上升最快方向向量 |
bigram 模型 前向 + softmax + NLL + 反向传播举例说明
py
logits = x @ W
probs = softmax(logits)
loss = -log(probs[target])梯度链条:W → logits → probs → loss
Luca 的理解:因果链!模型参数 W 是因,loss 是果,我们要看 W 变化一点点的话 loss 会怎么走,那么偏导数无疑是最佳的选择,它告诉你 W 往哪边动,Loss 会下降最快
更新参数需要:
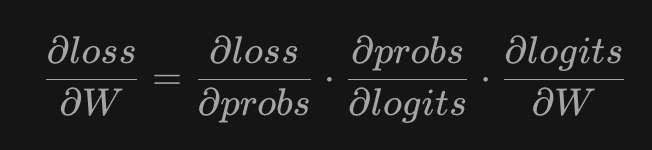
- 链式法则,层层影响相乘,误差能往回传,这就是反向传播的数学基础
- 链式法则帮我们把 Loss 对 W 的敏感度“一路传回去”
- PyTorch 自动帮你做这个乘法链(autograd)
问题:为什么更新参数要对 loss 对模型参数 w 求偏导?
让我们回顾下机器学习的目标:
让模型预测更准 → 让 Loss(损失函数)变小 → 找到能让 Loss 最小的模型参数 w
要想改变 w,让 Loss 更小,就得知道 “往哪个方向动 w,Loss 会下降得最快”
这个事情,就需要数学登场了!数学早就发明了解法:
梯度(偏导数)指向 Loss 增加最快方向,所以我们往梯度的反方向走 → Loss 降最快
因此,偏导数告诉你 w 改一点点,Loss 会变好还是变坏
数学基础
📊 核心概念(必须掌握)
1. 导数的基本定义
f'(x) = lim(h→0) [f(x+h) - f(x)] / h- 含义:函数在某点的变化率
- 几何意义:曲线的切线斜率
- 在反向传播中:表示损失对参数的敏感度
2. 偏导数(Partial Derivative)
对于多变量函数 f(x, y, z):
∂f/∂x:只看 x 变化时 f 的变化率(其他变量固定)- 在反向传播中:每个参数都有独立的梯度
3. 链式法则(Chain Rule) ⭐⭐⭐
这是反向传播的核心!
如果 z = f(g(x))
则 dz/dx = (dz/dg) × (dg/dx)神经网络例子:
输入 → 线性层 → 激活函数 → 损失
x → z=Wx+b → a=σ(z) → L
反向传播:
∂L/∂W = (∂L/∂a) × (∂a/∂z) × (∂z/∂W)
↑ ↑ ↑
损失对激活 激活对线性 线性对权重4. 常见函数的导数
你需要知道这些基本求导规则:
| 函数 | 导数 | 用途 |
|---|---|---|
x² | 2x | 理解二次损失 |
eˣ | eˣ | Softmax |
ln(x) | 1/x | 交叉熵损失 |
1/(1+e⁻ˣ) | σ(x)(1-σ(x)) | Sigmoid 激活 |
max(0, x) | 1 if x>0 else 0 | ReLU 激活 |
🎯 实际需要的微积分水平
最低要求(能用框架)
- ✅ 理解导数是"变化率"
- ✅ 会用链式法则
- ✅ 知道梯度下降:
w = w - lr × ∂L/∂w
推荐掌握(深入理解)
- ✅ 会手推简单网络的梯度
- ✅ 理解为什么梯度消失/爆炸
- ✅ 能看懂论文中的数学推导
不需要(太深入)
- ❌ 复杂的积分计算
- ❌ 微分方程
- ❌ 泛函分析
- ❌ 测度论
📚 学习路径建议
阶段 1:基础够用(1-2 周)
- 导数定义 + 几何意义
- 求导规则:加减乘除、复合函数
- 链式法则:多层嵌套
- 偏导数:多变量函数
阶段 2:实战验证(边学边做)
python
# 手动计算一个简单网络
import numpy as np
# 前向传播
x = 2.0
w = 3.0
b = 1.0
z = w * x + b # z = 7
a = max(0, z) # ReLU, a = 7
loss = (a - 10)**2 # L = 9
# 反向传播(手推)
dL_da = 2 * (a - 10) # = -6
da_dz = 1 if z > 0 else 0 # = 1
dz_dw = x # = 2
# 链式法则
dL_dw = dL_da * da_dz * dz_dw # = -6 × 1 × 2 = -12
# 验证:w 增加一点,loss 应该减少
w_new = w + 0.01
z_new = w_new * x + b
a_new = max(0, z_new)
loss_new = (a_new - 10)**2
print(f"梯度预测:{dL_dw}") # -12
print(f"实际变化:{(loss_new - loss) / 0.01}") # ≈ -12 ✓🔑 关键点总结
反向传播的本质:
- 前向传播计算输出
- 反向传播用链式法则逐层计算梯度
- 梯度下降更新参数
需要的微积分:
- 🎯 导数 = 变化率
- 🎯 链式法则 = 梯度传播
- 🎯 偏导数 = 多参数优化
学习建议:
- 先理解概念(不要被公式吓到)
- 从简单例子开始手推
- 用代码验证你的理解
- 先会用,再深究理论
你不需要成为数学家,但需要对微积分有直觉性的理解。PyTorch/TensorFlow 会帮你自动计算梯度,你只需要理解它在做什么!